

|
Outils logiciels pour les cours Paris II
Cours Paris II
Stages/ Thčses/ Séminaires |
StreamingDocument technique programme colab pour un flux twitter On prend comme référence le programme suivant https://github.com/alassou/TD-Up2/blob/master/TD_dashboard_2tickers.ipynb. Ce programme est décomposé en différentes parties :
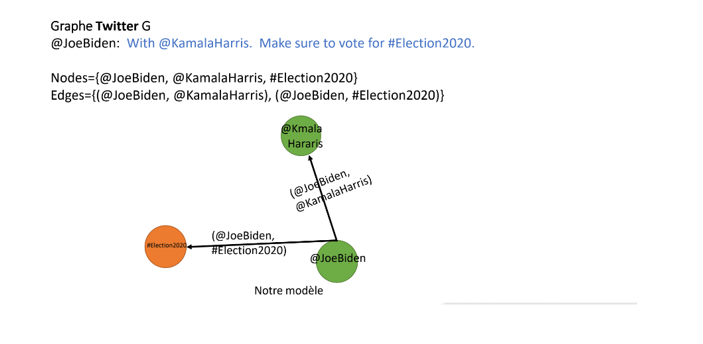
I. Interface avec le serveur et les variables asynchrones I. La structure des tweets Twitter envoie un flux de tweets ŕ partir de mots clés. On transforme chaque tweet en un ensemble d'arętes d'un graphe. Les tweets publiés par des comptes publics peuvent ętre récupérés ŕ l'aide de l'api streaming qu’on utilise dans notre cas. Pour utiliser les API Twitter, il est nécessaire d'avoir un compte développeur. Une fois réalisé, il nous faut créer une application pour pouvoir obtenir des clés et jetons afin de s'authentifier sur l’API. Toutes les API Twitter qui renvoient des tweets fournissent ces données codées ŕ l'aide de la notation JSON. Le format JSON est basé sur des paires clé-valeur, avec des attributs nommés et des valeurs associées. Ces attributs et leur état sont utilisés pour d’écrire les objets. La figure ci-dessous est un exemple d'un tweet émis par l'API Twitter. Les informations fournies contiennent des données relatives au tweet : date de création du tweet, texte du tweet, adresses URL ou mentions d'utilisateur, etc. Des informations sur Retweet sont également fournies avec les informations d'origines. Les informations concernant le créateur de la publication sont _également associées aux informations de tweet. /images//json.PNG| II. La transformation des tweets en arętes Chaque Tweet a un auteur, un message, un ID unique, un horodatage de sa publication et parfois des métadonnées géographiques partagées par l'utilisateur. Chaque utilisateur a un nom Twitter, un identifiant, un nombre de followers et, le plus souvent, une biographie du compte. Avec chaque tweet, nous générons également des objets "entité", qui sont des tableaux de contenus communs de tweet tels que les hashtags, les mentions, les médias et les liens. Prenons un exemple d’un Tweet:  Le JSON suivant illustre la structure de ces objets et certains de leurs attributs :  La fonction create graph permet de transformer du json en un graphe. Essentiellement elle prend comme paramčtre « data », on transforme ce paramčtre en dictionnaire. La variable user_screen_name : nous donne tous les noms d’utilisateurs Timestamps - Il s'agira d'une valeur d'horodatage qui sera ajoutée ŕ chaque événement fourni par l'API de diffusion en continu. Elle aidera ŕ établir l'ordre de l'événement en fournissant une granularité en millisecondes associée aux événements. ['entities'] Les entités fournissent des métadonnées et des informations contextuelles supplémentaires sur le contenu publié sur Twitter. La section des entités fournit des tableaux d'éléments courants inclus dans les Tweets : hashtags, mentions d'utilisateurs, liens, tickers boursiers (symboles), sondages Twitter et médias joints. ['entities'] ['hashtags'] Représente les hastags qui sont dans le tweet. Le graphe qu’on va obtenir: V. Les différents paramčtres k étant la taille du réservoir, tau la longueur de la fenętre, lambda le décalage temporel, tracking le mot clé pour filtrer le flux Twitter, threshold le seuil de la taille de la composante en dessous duquel la composante est ignorée, et timeout la durée totale de la capture. VI. L’interface graphique Pour l’interface graphique, essentiellement on récupčre les données stockés dans le fichier csv et on affiche les différents paramčtres (windows_counter, nśuds, arrętes, diamčtre, ticker1, ticker2). On veut afficher les courbes chaque nbp qui est un paramčtre a indiqué dans le formulaire. Sachant pour la variable dm, on a multiplié le diamčtre par 5. On utilise Plotly pour la visualisation graphique, est une entreprise qui développe des outils d’analyse et de visualisation de données tels que dash et chart studio. Il a également développé des bibliothčques d'interface de programmation d'application (API) graphiques open source pour Python, R, MATLAB, Java et d'autres langages de programmation informatique VII. Les possibilités d'évolution
|
 |
|