Elements de base |
Elements avancťs |
On trouve ici quelques ťlťments simples sur SQL. Les informations prťsentťes sont trŤs sťlťctives et partielles. La rťference la plus complŤte : www.mysql.org.
"Structured Query Langage" ou SQL est une norme dťfinissant un ensemble de commandes pour interroger et gťrer une base de donnťes, ces commandes ťtant disponibles pour l'ensemble des SGBD standards (SystŤme de gestion des bases de donnťes) et implťmentant la norme. Les bases de donnťes sont structurťes en tables, une table est un objet ŗ plusieurs colonnes ou champs et contenant un ensemble d'enregistrements-lignes (ou tuples ou occurences), chaque enregistrement sur la table renseignant les diffťrents champs. On considŤre ici une table qu'on appelle Client :
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
| Durand | Henri | 12 | Luxembourg |
| Meunier | Dominique | 34 | France |
| Ponder | Alain | 89 | Belgique |
Ici, on a 4 colonnes-champs : nom, prenom, age, pays et 4 enregistrements-lignes qui correspondent aux noms 'Dupont', 'Durand', etc...
La base de donnťes que l'on considŤre ici ŗ titre d'exemple contient la table Client et une autre table :
| idAchat | idProduit | nom | date |
| 1 | 129 | Meunier | 2005-12-31 |
| 2 | 17 | Meunier | 2005-11-06 |
| 3 | 23 | Durand | 2006-01-06 |
| 4 | 2 | Durand | 2006-02-17 |
La table Client retient des informations sur chaque client, la table Achat retient des informations sur les achats. Noter qu'ŗ partir d'un enregistrement de Achat, il est possible de retrouver les informations sur le client qui a fait cet achat, via le fait que l'on dispose du nom de la personne qui a achetť dans la table Achats. Une base de donnťes sťpare donc les donnťes en tables pour assurer un stockage optimal de l'information, mais des informations ťvoluťes reposant sur les informations contenues dans plusieurs tables peuvent Ítre retrouvťes : par exemple, on verra qu'ŗ partir de la base de donnťes courante, il est possible d'obtenir l'age moyen des individus qui ont achetť un produit particulier.
SQL permet de crťer des tables, ie de dťfinir le nombre et le nom des colonnes de chaque table et le type de donnťes que l'on va avoir dans chaque colonne. SQL permet d'insťrer des enregistrements dans les tables. Le langage permet enfin de consulter les informations qui ont ťtť rentrťes dans une table.
Le schťma relationnel d'une base de donnťe est une reprťsentation schťmatique de la base de donnťe. On donne le schťma de la base de donnťes minimaliste utilisťe ici :
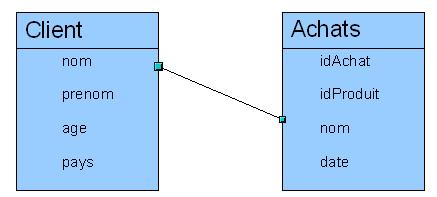
La dťmarche de conception d'une base de donnťe consiste ŗ ťtablir un schťma relationel pour la base de donnťe dont on a besoin. L'ťtablissement de ce schťma est assez direct dans le cas oý l'information manipulťe n'est pas trop complexe, au delŗ, des mťthode de conception existent : Merise, UML avec des techniques pour passer des schťma issus de ces mťthodes vers des schťma relationnels.
Le document qui suit prťsente les fonctions de base du SQL : consultation de table, modification de table, crťation de tables. Il existe beaucoup d'autres fonctions dťfinies par le langage SQL. Ces fonctions ne sont pas ťvoquťes ici et permettent une gestion beaucoup plus poussťe des bases de donnťes (gestion des droits de diffťrents individus, gestion des ťvenements...), des rťferences peuvent Ítre trouvťes sur le Web ou dans des ouvrages.
Notez que toute requÍte SQL doit Ítre terminťe par ';'.
La requÍte SELECT demande le renvoi d'enregistrements au sein d'une table, son schťma gťnťral est :
Ici, on appelle la rťcupťration des valeurs des champs spťcifiťs aprŤs le SELECT, pour les enregistrements contenus dans la table indiquťe aprŤs le FROM et pour les enregistrements rťpondant aux conditions spťcifiťes aprŤs le WHERE.
Par exemple :
Cette requÍte renvoie :
| nom | prenom |
| Dupont | Sylvie |
| Durand | Henri |
| Meunier | Dominique |
| Ponder | Alain |
Autre exemple :
Cette requÍte renvoie :
| nom | prenom |
| Dupont | Sylvie |
Le logiciel auquel est passť la commande va d'abord ťliminer les ťlťments qui ne rťpondent pas ŗ la condition spťcifiťe par le WHERE :
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
Le logiciel ne renvoie que les colonnes attribuťes spťcifiťes aprŤs le SELECT.
| nom | prenom |
| Dupont | Sylvie |
Quand on ne veut pas choisir quels attributs/ colonnes sťlťctionner :
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
| Ponder | Alain | 89 | Belgique |
Ici, * signifie tous les champs, la requÍte correspond donc au fait de renvoyer tous les champs pour l'ensemble des enregistrements tels que le champ "age" est rempli d'une valeur supťrieure ou ťgale ŗ 78. Ce qui se passe :

On peut enchainer des condition avec des opťrateurs logiques :
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
| Ponder | Alain | 89 | Belgique |
On peut classer les occurences renvoyťes :
| nom | prenom | age | pays |
| Ponder | Alain | 89 | Belgique |
| Meunier | Dominique | 34 | France |
| Durand | Henri | 12 | Luxembourg |
| Dupont | Sylvie | 78 | France |
On constate que l'on a les enregistrements qui sont classťes par prenom dans l'ordre alphabťtique.
On peut classer les occurences renvoyťes par ordre dťcroissant :
Le mot clť DESC demande le classement dans l'ordre dťcroissant.
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
| Meunier | Dominique | 34 | France |
Schťma gťnťral de la commande qui sert ŗ rentrer un enregistrement dans une table :
Exemple : On travaille sur la table INDIVIDUS, on veut rentrer un nouvel inividu (ie un nouvel enregistrement dans cette table) : Auburtin Alexandre agť de 20 ans, franÁais, en fonction du schťma de la commande decrit plus haut, la commande va Ítre :
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
| Durand | Henri | 12 | Luxembourg |
| Meunier | Dominique | 34 | France |
| Ponder | Alain | 89 | Belgique |
| Auburtin | Alexandre | 20 | franÁais |
A supposer que l'on veuille rentrer un individu dont on ne connaÓt ni l'‚ge ni le pays : Renoud Lucas, on passe la commande :
| nom | prenom | age | pays |
| Dupont | Sylvie | 78 | France |
| Durand | Henri | 12 | Luxembourg |
| Meunier | Dominique | 34 | France |
| Ponder | Alain | 89 | Belgique |
| Auburtin | Alexandre | 20 | franÁais |
| Renoud | Lucas |
Schťma gťnťral de la commande qui sert ŗ ťliminer un enregistrement d'une table :
Cette requÍte permet d'ťliminer l'ensemble des enregistrements-lignes de la tables. La requÍte ťlimine l'ensemble des enregistrements de la table spťcifiťe qui respectent les conditions spťcifiťs.
On veut enlever toutes les occurences des gens qui ont plus de 70 ans (ou 70 ans) dans la table :
On obtient :
| nom | prenom | age | pays |
| Durand | Henri | 12 | Luxembourg |
| Meunier | Dominique | 34 | France |
| Auburtin | Alexandre | 20 | franÁais |
| Renoud | Lucas |
Schťma gťnťral de la commande qui sert ŗ mettre ŗ jours des champs :
On donne un exemple :
On obtient :
| nom | prenom | age | pays |
| Durand | Henri | 13 | Luxembourg |
| Meunier | Dominique | 35 | France |
| Auburtin | Alexandre | 21 | franÁais |
| Renoud | Lucas |
On suppose avoir une autre table qui fait rťference ŗ la table INDIVIDUS : la table ACHATS qui enregistre des achats, cette table est ainsi renseignťe :
| idAchat | idProduit | nom | date |
| 1 | 129 | Meunier | 2005-12-31 |
| 2 | 17 | Meunier | 2005-11-06 |
| 3 | 23 | Durand | 2006-01-06 |
| 4 | 2 | Durand | 2006-02-17 |
On peut avoir besoin de l'information contenue dans plusieurs tables pour rťpondre ŗ certaines requÍtes, on considŤre l'instruction suivante :
Cette requÍte renvoie :
| nom | prenom | age | pays | idAchat | idProduit | 7 | |
| Meunier | Dominique | 35 | France | 1 | 129 | Meunier | 2005-12-31 |
| Meunier | Dominique | 35 | France | 2 | 17 | Meunier | 2005-11-06 |
| Durand | Henri | 13 | Luxembourg | 3 | 23 | Durand | 2006-01-06 |
| Durand | Henri | 13 | Luxembourg | 4 | 2 | Durand | 2006-02-17 |
Supposons que l'on veuille savoir les idProduits achetťs par des luxembourgeois : nous avons besoin de connaÓtre les informations des deux tables Client et Achats.
La requÍte :
| nom | prenom | age | pays | idAchat | idProduit | 7 | |
| Durand | Henri | 13 | Luxembourg | 3 | 23 | Durand | 2006-01-06 |
| Durand | Henri | 13 | Luxembourg | 4 | 2 | Durand | 2006-02-17 |
On prťsente ici des opťrateurs utiles qui permettent d'obtenir des moyennes sur des colonnes, d'obtenir les valeurs maximales d'une colonne etc...
Le schťma gťnťral pour le SELECT MAX est :
On donne un exemple :
| MAX(age) |
| 35 |
Un autre exemple :
| AVG(age) |
| 23.0000 |
Un autre exemple :
| COUNT(age) |
| 3 |
Un autre opťrateur possible de ce type est le SELECT MIN() On peut raffiner l'utilisation des ces opťratuers. Le GROUP BY est possible avec tous les opťrateurs prťsentťs plus haut, il consiste ŗ calculer la moyenne, le max, non pas sur l'ensemble des occurences, mais sur chaque groupe d'occurences reliťes selon un certain critŤre. Par exemple, on peut calculer la moyenne d'age en fonction du pays, le max d'age en fonction du pays
Par exemple :
| AVG(age) | pays |
| 35.0000 | France |
| 21.0000 | franÁais |
| 13.0000 | Luxembourg |
Autre exemple :
| MAX(age) | pays |
| 35 | France |
| 21 | franÁais |
| 13 | Luxembourg |
A partir des requÍtes proposťes dans la section prťcťdente, il est possible d'envisager des requÍtes plus complexes avec une sťmantique plus riche. Par exemple, on peut vouloir savoir qui est la personne la plus agťe parmis celles de la base. La stratťgie d'exploration d'une table qui vient naturellement aux individus consiste ŗ regarder quel est l'age maximum dans la base pour ensuite voir ŗ quelle(s) occurence(s) cet age correspond. SQL fonctionne de la mÍme faÁon, si dans notre base, on veut connaÓtre le nom de la personne ŗ ‚ge max :
Cette requÍte renvoie :
| nom | prenom | age | pays |
| Meunier | Dominique | 35 | France |
L'instruction CREATE TABLE a le schťma suivant :
La dťfinition de champ a minima correspond au fait de donner un nom de champ et un type de champ.
Par exemple :
Les types suivants sont possibles :
| Nom du type | Description |
| INTEGER | Valeur entiŤre |
| FLOAT(n) | Valeur rťelle avec une prťcision dťfinie par n. |
| VARCHAR(n) | Chaine de caractŤres avec au plus n caractŤres |
| DATE | Une date, on peut rentrer une valeur en passant une chaine 'YYYY-MM-DD' |
Certaines options peuvent Ítre dťfinies pour un champ aprŤs la dťfinition de son type :
Attention, il ne faut pas dťfinir plusieurs clťs primaires : il faut qu'il n'y ait qu'une seule dťfinition. La premiŤre instruction prťsentťe ici dťfinie nomChamp1 comme une clť ťtrangŤre d'une autre table. La deuxiŤme instruction correspond au cas oý un seul champ ne suffit pas ŗ dťfinir une clť, mais le cas oý plusieurs champs sont nťcessaires. Par exemple, dans la plupart des cas oý on dťfinit une rťfťrence de produit, on a ce champ qui dťfinit une dťpendance fonctionnelle sur l'ensemble des autres champs et on peut se servir de ce champ comme clť primaire.
Cette instruction est ŗ manipuler avec une certaine prudence, elle permet d'ťliminer une table et toutes les occurences enregistrťes dans cette table. Son schťma est le suivant :
Ici il ne s'agit pas de modifier les occurences d'une table, il s'agit de modifier la dťfinition d'une table. On peut ajouter des champs ŗ une table, enlever des champs d'une table etc... La commande est ALTER TABLE, sa syntaxe est la suivante pour ajouter un champ :
Par exemple, on ajoute un champ date de naissance pour les clients :
La table Client devient alors :
| nom | prenom | age | pays | dateNaissance |
| Durand | Henri | 13 | Luxembourg | |
| Meunier | Dominique | 35 | France | |
| Auburtin | Alexandre | 21 | franÁais | |
| Renoud | Lucas |
Pour ťliminer un champ :
Par exemple, puisque on a rajouter un champ date de naissance, on pourra recalculer l'age des clients ŗ partir de leur date de naissance (se posera un problŤme pour l'ensemble des clients pour lesquels on n'a pas rťcupťrť la date de naissance au moment de leur enregistrement) :
On passe la requÍte :
La table Client devient :
| nom | prenom | pays | dateNaissance |
| Durand | Henri | Luxembourg | |
| Meunier | Dominique | France | |
| Auburtin | Alexandre | franÁais | |
| Renoud | Lucas |
L'instruction :
Renvoie une description de la table. Par exemple :
Renvoie :
| Field | Type | Null | Key | Default | Extra |
| nom | varchar(200) | YES | |||
| prenom | varchar(100) | YES | |||
| pays | varchar(70) | YES | |||
| dateNaissance | date | YES |
Dans le cas oý vous voulez renseigner un champ date, utiliser le format :
Par exemple : '2005-06-21' sera interprťtť comme le 21 juin 2005. Dans le cas d'une date non valide, la date sera '0000-00-00'. Pour le cas d'un format time stamp, on peut communiquer avec en utilisant le format : 'AAAA-MM-JJ HH:MN:SS.nnn'. Pour la manipulation de dates, on dispose de diffťrente fonctions. Soit date un champ DATE, YEAR(date) renvoie l'annťe de la date, MONTH(date) et DAY(date) renvoient respectivement les mois et dates. Enfin, now() renvoie la date courante.
A supposer que l'on ait une table individus avec un champ dateNaissance. On peut approximer l'age des individus par : YEAR(now())-YEAR(dateNaissance) est une apprxoximation de l'age d'un individu. Une syntaxe avancťe pour avoir la moyenne d'age des individus de cette table :
'%' est un symbole qui signifie toutes les chaines de caractŤres. Si on veut rťcupťrer tous les individus de Client dont le nom commence par 'D', on utilise LIKE qui compare deux chaines de caractŤres :
| nom | prenom | pays | dateNaissance |
| Durand | Henri | Luxembourg |
On veut maintenant rťcupťrer l'ensemble des chaines qui contiennent 'on' :
| nom | prenom | pays | dateNaissance |
| Durand | Henri | Luxembourg | |
| Auburtin | Alexandre | franÁais |
La dťpendance fonctionnelle est une relation entre attributs. On dit qu'un attribut a1 est en dťpendance fonctionnelle sur un autre attribut a2 si pour toute occurence de a1, on a une unique occurence de a1 qui lui correspond. Par exemple, soient un attribut referenceProduit qui correspond ŗ la reference d'un produit et un attribut prix, on a une relation de dťpendance fonctionnelle entre referenceProduit et prix. Ceci signifie que pour tout produit, on a un prix unique qui lui est associť. On note : referenceProduit -> Prix.
La notion de dťpendance fonctiontielle intervient dans la conception des bases de donnťes. Les bases de donnťes sont un moyen de stocker de l'information ŗ partir d'une modťlisation de ces donnťes. La dťmarche de conception consiste ŗ retenir des donnnťes que l'on analyse les relations de dťpendances fonctionnelles. On dispose ensuite d'un certains nombres de rŤgles qui nous permettent de dťduire des relations de dťpendance fonctionnelle des tables de base de donnťes. La conception des tables ŗ partir des bases de donnťes, si elle rťpond ŗ certaines propriťtťs, est dite en forme normale. On a plusieurs niveaux de normalisation. La normalisation centrale est la troisiŤme forme normale d'une table. Ces formes normales garantissent une optimisation du stockage de l'information.